
7 Common Technical SEO Mistakes
Technical SEO can seem daunting to many individuals. However, if you manage or own a website, then you need to understand at least the basic technical SEO elements. Understanding some of the common technical SEO mistakes is a great place to start to gain holistic SEO base knowledge beyond just keywords and content.
Technical SEO mistakes can very easily set a site back in organic search. Here are 7 common technical SEO mistakes to make sure your website avoids these costly mistakes.
1. Robots.txt disallow all
A robots.txt file is a file at the root domain of your site that provides instructions on how search engines should crawl your site (most domains and subdomains have it at https://www.yoursite.com/robots.txt).
Essentially, a site’s robots.txt file acts as a blueprint for search engines (like Google and Bing) to discover your site (in order to index and rank your site, a search engine must crawl it first).
Robots.txt files provide specific directives about pages and areas of your site to avoid by including disallow statements. It can be a great way to manage duplication and avoid crawl traps for large sites. However, it can also block search engine access to critical content.
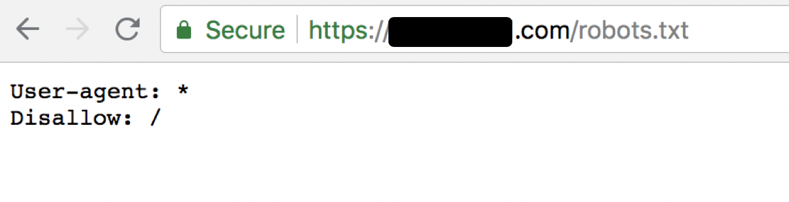
The biggest mistake a site can make is to accidentally robots.txt disallow your entire site or even important pages.
Here’s what that disallow all looks like:
2. Mobile unfriendliness
Having a mobile-friendly website is a no-brainer these days. If you don’t have one, then you should make this your #1 SEO or website priority right now.
Google not only penalizes sites that aren’t mobile-friendly, but the majority of users are on mobile devices, so a mobile-friendly site is a necessity for good user experience.
Mobile friendliness is even more important for businesses with a physical location. Google has said that 4 out of 5 searches have local intent. Out of those searchers, 88% use a smartphone.
Google has launched various mobile-friendly updates over the past couple years and has moved to a mobile-first index this year.
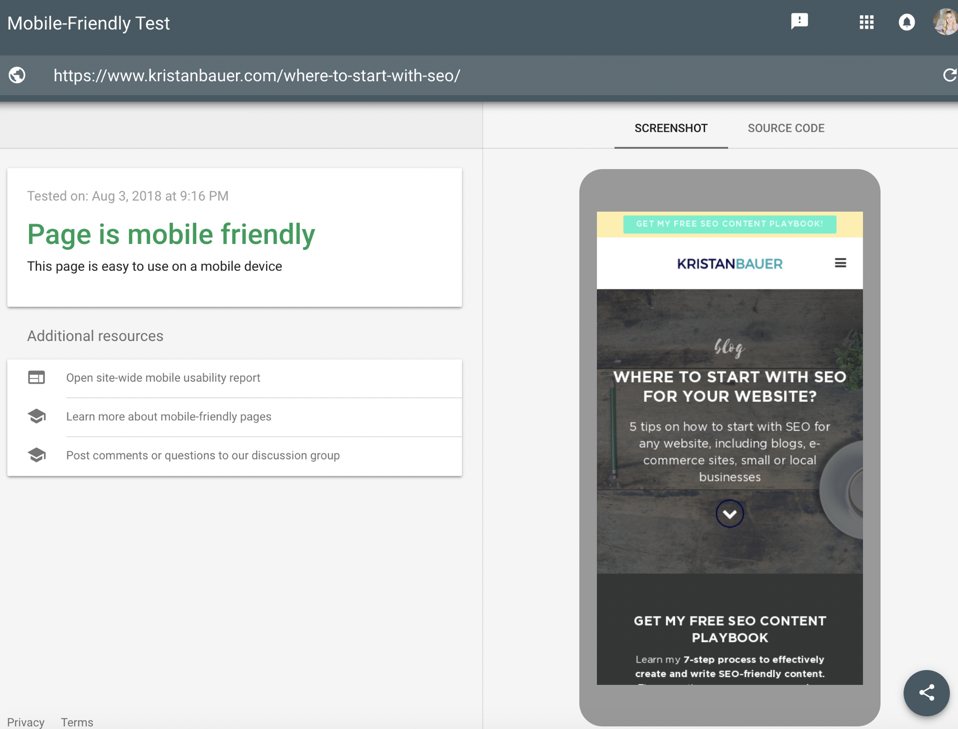 Source: https://search.google.com/test/mobile-friendly
Source: https://search.google.com/test/mobile-friendly
3. Slow page speed
Not paying attention to site latency and page speed is a huge mistake. Particularly now that Google has site speed updates that can negatively impact the slowest of websites.
Page speed is so critical these days – not only for better search ranking but also for user experience and conversion.
A fast site can greatly improve your conversion value. The converse is true for a slow site. For every 1 second delay in page load time, there is a 7% drop off in conversion.
Page speed has been a ranking factor in Google since 2010 for desktop searches and recently became one for mobile searches. Faster page load times continue to be an important differentiation for top ranking sites. In a perfect world, desktop sites would load in less than 3 seconds and mobile sites less than 1 second.
4. Internal linking errors
Internal linking is one of the most important onsite SEO levers that any website can use effectively and strategically. However, many websites make a common mistake of linking to pages they shouldn’t.
This SEO mistake includes linking to pages such as:
- Error or broken page’s (404 page not found errors)
- Redirects (301, 302, JavaScript, etc.)
- Non-canonical URLs
Linking to the canonical, end-state URL is an SEO best practice and has many benefits, such as better crawl efficiency, better indexation and better distribution of link equity to the correct pages.
Use crawl tools, such as Screaming Frog, to crawl your website and uncover these internal linking errors.
 Source: https://www.screamingfrog.co.uk/seo-spider/
Source: https://www.screamingfrog.co.uk/seo-spider/
5. Misuse of search directives
Search directives can come in a few different formats, including HTTP status codes, robots.txt crawl directives and also meta robots tags or x-robots tags.
Some of the most common meta robots tags include the following variations:
- <meta name=”robots” content=”index, follow”>
- <meta name=”robots” content=”noindex”>
- <meta name=”robots” content=”noindex, nofollow”>
Essentially, these are directives telling search engines either to index and crawl the page or not index (“noindex”) and don’t crawl the page (“nofollow”).
The default is “index,follow” a page’s contents so if you don’t have a meta robots tag on your page, then search engines will index and crawl it (unless you tell it not to).
Making sure you have the right tags across pages you want indexed and crawled is an important technical SEO housekeeping item.
6. Lack of canonical tagging
Rel=canonical tags are search annotations included in the HTML source code. Rel=canonical tags are helpful to search engines and websites for a few reasons:
- They can manage duplicate pages
- They can control indexation
- They consolidate link equity
Ideally, every page on a website should have a rel=canonical tag either to itself (a self-referencing canonical tag) or to another page if it’s duplicate.
If you have near duplicate pages (such as parameter pages, tracking codes, page sort filters, etc.), then using a canonical tag to the one page you want indexed is helpful.
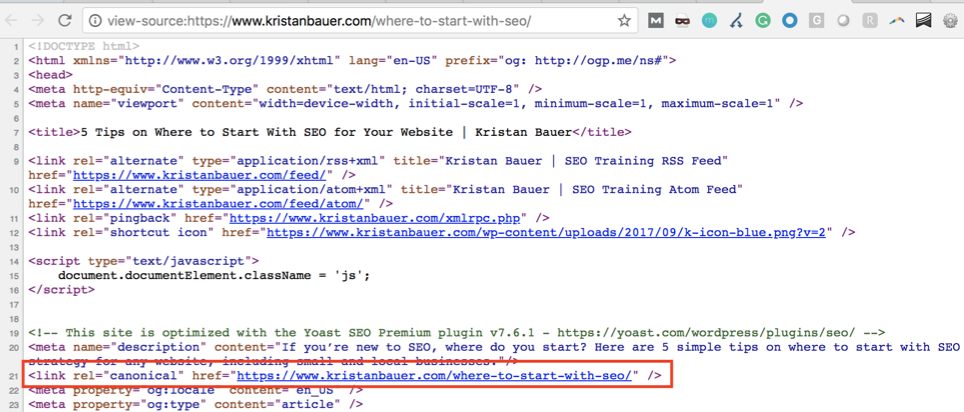 Source: view-source:https://www.kristanbauer.com/where-to-start-with-seo/
Source: view-source:https://www.kristanbauer.com/where-to-start-with-seo/
7. Pages indexed that shouldn’t be
Excess indexation is a very common issue among websites. This includes legacy pages indexed, duplicate pages indexed and even staging site pages indexed.
An easy way to find pages you don’t want to be indexed is to do various site operator searches (such as ‘site:yourwebsite.com’). Start by searching your full domain, you can likely narrow down by page type of individual site section (such as “site:yourwebsite.com inurl:/pages/”).
Once you identify pages that you don’t want to be indexed, there are a few options to remove them from any search index by either:
- Adding a meta robots noindex tag
- Adding a rel=canonical tag to another page
- 301 redirecting to another page
Conclusion
If you’re new to technical SEO, it can be challenging to grasp. However, understanding basic elements and common technical SEO mistakes can help any website (and are a necessity for any website). Technical SEO mistakes have the potential to make or break a website so make sure your site isn’t guilty of these!
Have you seen any other common technical SEO mistakes? Or have you found any others on your site? Please share in the comments below!
Kristan is an independent consultant with 15 years of experience in the SEO industry. Kristan previously founded the award-winning SEO agency Conifr. She’s worked in agency and in-house SEO leadership positions, most notably as the SEO Director at Zillow Group, overseeing a channel that received over one billion web visitors a year. Kristan is a freelance SEO consultant who built and sold a seven-figure agency and now enjoys helping others develop their freelance business.

